
Telegraph CQ Getting Started Document
System Requirements
The TelegraphCQ system was developed on RedHat Linux x86 and MacOS 10.2
and has only been built on these platforms.
Early-access Software
Thank you for
trying the TelegraphCQ 0.2 alpha release!
This release is an early-access implementation that has NOT been
optimized for performance or verified through rigorous quality testing.
This version is research code, and we highly recommend that you back up
any existing, critical data before running it.
We'd love to hear back about any problems you face.
Please let us know if you are using TelegraphCQ for any applications.
You can send feedback to tcqfeedback@db.cs.berkeley.edu |
Software Requirements
In addition to the software required to build and run PostgreSQL, the
TelegraphCQ distribution requires the following additional packages:
NOTE: Depending on the install location
you use for the software packages listed below, you may need to pass
the --with-libraries
and--with-includes options to the configure script so
that it can find the appropriate libraries and include files during the
build configuration process.
ALL Platforms
- OSSP MM: TelegraphCQ uses this open source shared memory
library as the basis for a shared memory version of the
PostgreSQL memory allocater. The Telegraph system requires
at least version 1.2.1 of this library. It can be obtained at the
following URL: http://www.ossp.org/pkg/lib/mm
Mac OSX
- Mac OS X does not contain the poll system call, and instead
uses select. Mac users must obtain and install a poll emulation
library. The TelegraphCQ system has been tested with the
poll-emulator library available at: http://www.clapper.org/software/poll/
- The demo application requires the following extra software, which
is not included in MacOS X:
- GNU wget: The demo source uses this program to read traffic
sensor data from the network. wget can be installed via fink, or using the the
following tarball.
- GNU awk: Although a version of awk is installed with MacOS X,
the demo source requires features of GNU awk. gawk can be
obtained using fink, or
using
the the following tarball.
- The PostgreSQL interactive query utility will use the GNU
readline library, if available, to provide history for commands entered
into psql. This library is not installed on MacOS X, but can be
obtained via fink, or using
the the following tarball.
Building the System
- Install the software listed in the system requirements section
above
- Follow the directions listed in the PostgreSQL INSTALL file to build the system and create a
database. Remember to include the options mentioned above to name
the install locations of any required libraries and include
files.
Here is the abbreviated version:
- set up the following environment variables:
INSTALLDIR
|
The top level directory
where the TelegraphCQ installation should be placed during the make
install command
|
DBNAME
|
The name of the database
which will be created during the install process
|
PGDATA
|
The path to the directory
which will contain your database. This directory will be created
by the initdb command
|
-
./configure
--enable-depend --prefix=${INSTALLDIR}
--with-includes=extra-include-directories --with-libraries=extra-library-directories
--enable-depend
|
turn on dependency checking
|
--prefix
|
set the top level
directory into which 'make install' will install TelegraphCQ
|
--with-includes
|
name any additional
include
file directories which might be needed by configure when searching for
various features (e.g. mm, poll, readline)
|
--with-libraries
|
name any additional
library
directories which might contain libraries needed by configure when
searching for various features (e.g. mm, poll, readline)
|
gmake
- The PostgreSQL install guide recommends that you create a new
user which will own the database files and run the server. The
next steps are to create a data directory and change permissions on
that
directory to the correct user. If you have created a new user,
switch to that user and continue with the remainder of the installation
steps
gmake install ${INSTALLDIR}/bin/initdb --no-locale -D
${PGDATA}
${INSTALLDIR}/bin/pg_ctl start -D ${PGDATA} -llogfile
${INSTALLDIR}/bin/createdb ${DBNAME}
${INSTALLDIR}/bin/pg_ctl start -D ${PGDATA}
NOTE: Although the procedure outlined
above is the minimum necessary to get the system up and running, most
users will want to set up demonstration streams. This can be done
by using the 'make tcqdemosetup' makefile target instead of executing
steps 5-9 above. Please see the examples section of this document
for more information on the sample streams that are set up.
NOTE 2: TelegraphCQ 0.2 requires its own data directory and
databases. It will NOT work
with databases from other Postgres or TelegraphCQ releases. Make
sure that PGDATA points at an empty directory or a previously created
TelegraphCQ 0.2 database before running the setup steps above.
Starting TelegraphCQ
The TelegraphCQ system has been designed to integrate with standard
PostgreSQL As a result, you may start the postmaster in one of two ways:
- In normal PostgreSQL mode: In this mode, streaming queries
will not be available, but standard queries against PostgreSQL
relations
will work.
- In TelegraphCQ mode: queries that do not involve streams will be
processed in the same way as regular Postgres queries. Queries
that involve streams will be processed using the TelegraphCQ executor.
To start the system in TelegraphCQ mode, supply the following
additional arguments to the postmaster at startup:
| -t database |
This option tells the TelegraphCQ executor the name of the
database it should use to run queries. |
| -u username |
This option tells the TelegraphCQ executor the name of the
user running the queries |
| -G |
Tells the TelegraphCQ executor to run queries using the
CQEddy executor. |
-w
|
The port the TelegraphCQ Wrapper
Clearinghouse uses to accept connections. The default port is 5533
|
For example, to start TelegraphCQ with the Telegraph executor running
in the context of the user named telegraph user and the database named
telegraphdb, issue the following command:
pg_ctl start -o "-t telegraphdb -u
telegraphuser -G" -l /tmp/tcq.log
Note that the above command assumes that you have already initialized
and created the database telegraphdb and created the telegraph user
according to the procedure specified in the PostgreSQL documentation,
and have set the PGDATA environment variable to indicate the directory
that contains the telegraphdb database. The log output will be
placed in the file /tmp/tcq.log.
Client Applications
Client applications must be written to accommodate continuous
queries. In particular, because continuous queries never
end, client applications should use cursors to bound the size of
any particular result set returned from the server.
The PostgreSQL query client, psql, has been modified to submit SELECT
queries using cursors, and to fetch the result in batches.
Psql now accepts the following new arguments:
| -C |
Submit select queries using cursors. |
| -I n |
Query results will be fetched from the server in batches of n
rows.
The default value for n is 1 |
| -i m |
The query will be canceled after retrieving m rows.
By default the query will run until canceled by the user.
|
For more information on PostgreSQL cursor support, please see the
documentation for the DECLARE
CURSOR,FETCH,
and CLOSE
PostgreSQL SQL commands.
Overview of the TelegraphCQ Architecture
Unlike standard PostgreSQL which uses a separate process to serve each
client connection, TelegraphCQ runs all queries in a single PostgreSQL
executor so that query processing work may be shared amongst queries.
As shown in the Architecture diagram below, a separate
PostgreSQL process is forked for each client connection. This
process runs all queries that do not involve streams using the normal
PostgreSQL executor. When PostgreSQL receives a continuous query,
the front end parses and plans the query in shared memory. The
front end uses the output of the PostgreSQL optimizer to construct a
continuous query plan. Next, the frontend passes the plan to the
TelegraphCQ backend executor using a shared memory queue. The
backend receives the plan, and integrates it into the TelegraphCQ
Eddy. Finally, the eddy returns results to the appropriate
Postgres front end processes via shared memory result queues.
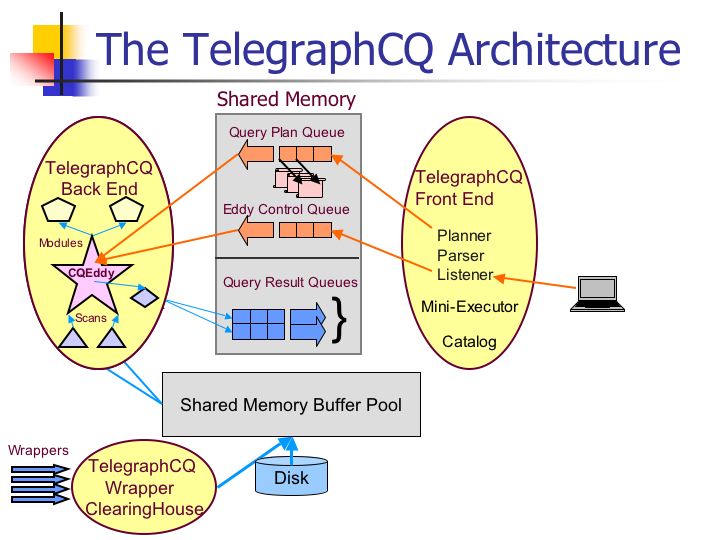
The TelegraphCQ Executor: Sharing Explained
The TelegraphCQ executor is a Continuous
Query Eddy. An eddy is a routing operator that contains a
number of modules that perform work on behalf of queries, and a number
of sources that provide input data. The eddy obtains data from
sources, determines which modules a particular tuple must visit before
processing completes. After a tuple has visited all required
modules, it is output by the eddy.
The continuous query plan consists of a number of distinct modules:
| filters |
These represent single-table qualifications in the query.
They are always of the form column OP constant. These filter modules
will be merged together by the eddy to form a grouped filter which can
evaluate filter predicates for multiple queries simultaneously. |
| SteMs |
The building blocks for continuous query joins. A SteM holds
tuples for a particular base relation or stream, and can be probed
efficiently to find data tuples which match a probe tuple. |
| Table or Stream Scans |
These scans are used to obtain data from TelegraphCQ streams
or regular PostgreSQL relations. |
Data Acquisition Mechanisms in TelegraphCQ
TelegraphCQ acquires data from external sources into streams.
These sources must connect to the TelegraphCQ system and identify
themselves prior to sending data. User-defined data acquisition
functions called wrappers allow substantial flexibility as to
how
that data is processed prior to entry into the Telegraph system and
insertion into a stream.
User-defined wrapper functions manage reading data from a networked
source, processing it, and returning it to system in the appropriate
format. These functions are declared and managed using the
PostgreSQL user-defined function infrastructure. A dedicated
wrapper clearinghouse process accepts connections from new data
providers, calls the appropriate wrapper functions in response to
data arrival or other events such as connection termination or after a
specified period of inactivity, and routes data tuples returned
by
the wrappers to the corresponding streams.
Streams
A stream appears to the user as if it were any other PostgreSQL table,
and is created using PostgreSQL DDL which is similar to the create
table
command. A stream may be either archived or unarchived. An
unarchived stream is never backed by disk storage, and is implemented
in
terms of shared-memory queues. An archived stream uses an
append-only access method to pass tuples to the rest of the system.
Streams are created using the DDL command CREATE STEAM which has the
following syntax:
CREATE STREAM streamname (colname datatype, …) type ARCHIVED |
UNARCHIVED
ARCHIVED streams will take data that is received from the wrapper and
insert it into a relation named ‘streamname’.
UNARCHIVED streams use shared memory queues to communicate
results between the wrapper clearinghouse process and the executor
which
scans the source.
Streams must have at one column named tcqtime and of type
typestamp. In addition this column must have the TIMESTAMPCOLUMN
constraint defined on it. Telegraph uses this column as the
timestamp for windowed query operations. Please see the CREATE
STREAM command in the SQL Reference guide.
Data Sources
TelegraphCQ supports acquiring data from two different types of
sources. PUSH sources initiate a connection to TelegraphCQ, send
some configuration information, and then send data rows to the
system. PULL sources provide a way for Telegraph to initiate
requests for data from other data sources.
Please see the TelegraphCQ Wrapper
Clearinghouse Documentation to learn how to write user-defined
wrapper functions and create sources.
For information on integrating Web based data sources with TelegraphCQ,
please look here
Introspective Query Processing: self-monitoring capability
TelegraphCQ has some special streams that report information about the
state of the system. Please look here
for more information on this feature.
Windows and Streams
Unlike normal relations, data streams typically do not end. It is
therefore useful to be able to define windows, or subsets of the
streams, which participate in a query result.
Each stream has a special time attribute that TelegraphCQ uses as the
tuple’s timestamp for windowed operations. Windows on a stream
are
defined in terms of a time interval relative to the most recently
arrived tuple. The timestamp for a join tuple is
defined as the maximum stream timestamp contained in the composite
tuple.
The creation of a new tuple that has a stream timestamp greater than
any seen so far marks the beginning of a new window for query
operations.
Running Queries Over Streams
Queries over data streams are run using the SQL SELECT statement.
Queries that contain streams do not support the full SELECT
syntax, and also include and extra WINDOW clause to specify the window
size for stream operations.
The modified SELECT statement has the following form:
SELECT <select_list>
FROM <relation_and_<pstream_list>
WHERE <predicate>
GROUP BY <group_by_expressions>
WINDOW stream[interval], ...
ORDER BY <order_by_expressions>;
The window clause may contain one window_expression per stream in the
query. A window expression specifies the correlation name for the
stream and the size of the sliding window expressed as a PostgreSQL
interval datatype.
All other clauses in the SELECT statement behave like the PostgreSQL
select statement with the following additional restrictions:
- windows may not be defined over PostgreSQL relations
- where clause qualifications that join two streams may only
involve columns, not column expressions or functions.
- where clause qualifications that filter tuples must be of the
form column op constant
- The where clause may contain AND, but not OR
- subqueries are not supported
- GROUP BY and ORDER BY select clauses may only appear if the
query also contains a window.
Reference
The following pages from the SQL Reference Guide describe TelegraphCQ
features:
Example
TelegraphCQ ships with a series of scripts which set up several example
streams. These scripts are located in the src/test/examples/demo
directory of the distribution.
To make it easy to run these scripts, run the command 'make
tcqdemosetup' from the top level Makefile. Make sure to set
the PGDATA environment variable to the location where the postgres data
directory is (or will be) located. This makefile target will:
1. run initdb and then create a database called sample if the
directory pointed to by ${PGDATA} does not exist
2. run the refresh script in the demo directory. This will clean
up existing database objects and recreate them. It will
then
start
up the datasources which provide data to the
streams.
Once this script runs, the following streams will be set up:
traffic.measurements
|
A stream which reports the speed
of traffic at various locations. updates are obtained each minute.
|
traffic.incidents
|
data about current traffic
incidents in the San Francisco Bay Area
|
network.tcpdump
|
Displays tcp packets currently
entering your system as provided by tcpdump. In order for this
source to work, tcpdump must be executable must be suid root.
|
web.quotes
|
Obtain a stock quote from a web
site. A value for the symbol column must be specified (either
through reference to another table or stream, or via a constant) in
order to get results. |
|
|
Sample Queries
At this point, you are ready to start the source application that will
provide data to the measurements stream and run some queries over it.
To run queries:
- Start the psql client as follows: psql –C databasename
- At the psql prompt, type a query such as: select * from measurements;
- Provided that the data source is currently sending information,
tuples should appear in your psql client. When you are finished
viewing query results, press control-C to cancel the query.
- You may now submit additional queries if desired
Here are some sample queries to get you started:
SELECT *
FROM traffic.measurements |
See the sensor readings as they become available. |
SELECT *
FROM traffic.measurements m
WHERE speed > 65 |
See readings for sensors where the traffic is speeding. |
SELECT m.speed, s.name
FROM traffic.measurements m, traffic.station s
WHERE m.stationId = s.stationId |
See the speed and the name of each sensor |
SELECT
ms.stationId, s.name,
s.highway,
s.mile, AVG(ms.speed)
FROM traffic.measurements ms, traffic.station s
WHERE ms.stationId = s.stationId
GROUP BY
ms.stationId, s.name,
s.highway, s.mile
HAVING ms.stationId > 999406
WINDOW ms ['30 minutes']
|
Get the average speed values from the sensors. Each average
will be computed using a 30 minute sliding window of sensor data. The
average values will be recomputed and sent to the user any time a data
item arrives that changes the data set.
|
select * from web.quotes where
symbol='ORCL'
|
obtain a stock quote for Oracle
|
select * from network.tcpdump
|
monitor TCP packets
|
|
|
More Information
For more information on the TelegraphCQ project, and to keep up to date
with future developments, please visit the Telegraph web page at http://telegraph.cs.berkeley.edu.
Users who want an overview of the TelegraphCQ implementation in its
current state should refer to the the paper:
TelegraphCQ: An Architectural Status Report: [PDF]
Sailesh Krishnamurthy, Sirish Chandrasekaran, Owen Cooper, Amol
Deshpande, Michael J. Franklin, Joseph M. Hellerstein, Wei
Hong, Samuel R. Madden, Fred Reiss, Mehul Shah.
To appear in: IEEE
Data Engineering Bulletin.
Other papers relating to TelegraphCQ referenced in this document:
TelegraphCQ: Continuous Dataflow Processing for an Uncertain
World. [PDF]
Sirish Chandrasekaran, Owen Cooper, Amol Deshpande, Michael J.
Franklin, Joseph M. Hellerstein, Wei Hong, Sailesh Krishnamurthy,
Samuel
R. Madden, Vijayshankar Raman, Fred Reiss, and Mehul A. Shah.
CIDR 2003
Continuously Adaptive Continuous Queries over Streams. [PDF]
Samuel R. Madden, Mehul A. Shah, Joseph M. Hellerstein and Vijayshankar
Raman. Continuously Adaptive Continuous Queries over Streams.
ACM SIGMOD Conference, Madison, WI, June 2002.
Using State Modules for Adaptive Query Processing [PDF]
Vijayshankar Raman, Amol Deshpande, Joe Hellerstein
Intl. Conf. on Data Engineering, 2003
Acknowledgements
We are grateful for comments and suggestions from other members of the
database systems research group at Berkeley, as well as researchers who
are building similar systems in other groups. This work has been
supported by National Science Foundation awards IIS-0208588,
IIS-0205647, IIS-0086057 and SI0122599 as well as funding from
Microsoft, IBM, Intel and the UC MICRO program.
The rapid development of TelegraphCQ was made much easier by our
ability to use and integrate with the PostgreSQL code base, and by our
use of the OSSP MM Shared Memory Allocation library as the basis for
the
newly added shared memory context.
The WebQuery components of this system use client portions from the W3C
Jigsaw project.