Telegraph is a new kind of system we call an adaptive dataflow engine. To understand the technology behind Telegraph, it's useful to describe what a dataflow engine is for, and why dataflow needs to be adaptive in the next generation of networked computer systems.
Dataflow
A dataflow engine is an execution environment that moves large amounts of data through a number of operators running on one or many machines. Programmers can use a dataflow engine by writing dataflow operators, and combining them together into pipelines, trees, or more complex dataflow graphs. Examples of traditional dataflow engines include database query engines, network packet filters, and even the simple shells and pipes in operating systems like UNIX and MSDOS.
Dataflow operators can be thought of as loops, which repeatedly receive
data from their inputs, and place data on their output. Some dataflow
operators have only one input (as in UNIX pipes and packet filters), while
others may have multiple inputs (e.g. relational Joins in database query
engines, or aggregation nodes in a sensor network). A typical abstraction
for a dataflow operator is an iterator, which is an object with
3 basic methods:
class iterator {
public:
void open(); // initializes state
outputType next(); // returns a chunk of data for output
void close(); // tears down state
private:
iterator inputs[]; // the inputs to this iterator in the dataflow graph
}
Some dataflow operators are pipelined, meaning that they produce data to their output before they finish receiving all the data from their inputs. All the operators used in Telegraph are pipelining; many of them were developed in the earlier CONTROL research projects at Berkeley. Other dataflow operators are batch operators, which must receive all their input data before generating any output data. An example of a batch operator is Sort.
Earlier work in both networking and database systems has focused on schemes to implement dataflow across multiple machines in both the wide area and on massively parallel clusters. One nice programming abstraction we use in Telegraph is the Exchange iterator (invented for the Volcano dataflow system), which encapsulates all inter-machine communication and load-balancing within an iterator, making it easy to develop a single-machine dataflow engine and extend it to work across multiple machines.
Adaptivity
A computer system is said to be adaptive if it in the course of its standard operation it repeatedly measures its environment, and decides how to take action based on such measurements. The actions in an adaptive system often affect the environment, and hence an adaptive system is in a constant feedback loop with its environment. This is sometimes described as "machine learning" or "intelligent systems", since the software seems to get better based on its "experience" of how its actions interact with the environment.
The design of Telegraph is predicated on the assumption that most of the exciting new computing problems will take place in very volatile, unpredictable environments. This includes the Internet, sensor networks, and wide-area federated software systems including peer-to-peer systems. In all these environments, performance is volatile: data rates change from moment to moment; machines and services speed up, slow down, disappear and reappear over time; code behaves differently from moment to moment; data quality changes from moment to moment. Also, all of these environments are data-intensive, focused on harnessing the computer as an information tool, not just a calculation tool.
Currently, Telegraph includes two basic adaptive dataflow techniques:
- Eddies are used in Telegraph to continuously reshape dataflow graphs to maximize performance. Eddies serve to adaptively route data through operators, continuously changing the order of operators in a dataflow graph by observing the rates at which operators consume and produce data. An eddy is implemented as a special iterator that can be injected into any dataflow graph (or subgraph) to make it adapt its shape. In our demonstrations of Telegraph on the web, we use eddies at the center of every graph we build. A technical paper on eddies is available on our website.
- Rivers are used in Telegraph to continuously load-balance work across multiple machines on a network. Rivers adaptively route data to different machines, by observing the rates at which the machines can handle additional work. A technical paper on rivers is also available from the Berkeley NOW website.
A Simple Telegraph FFF Server Architecture
We've deployed the Telegraph engine to integrated, summarize and browse Federated Facts on Figures (FFF) on the internet. In addition to the core Telegraph engine, the FFF system uses the Telegraph Screen Scraper (TESS), a tool for automatically filling out web forms and parsing results. The basic architecture of a simple single-node Telegraph server looks like the following:
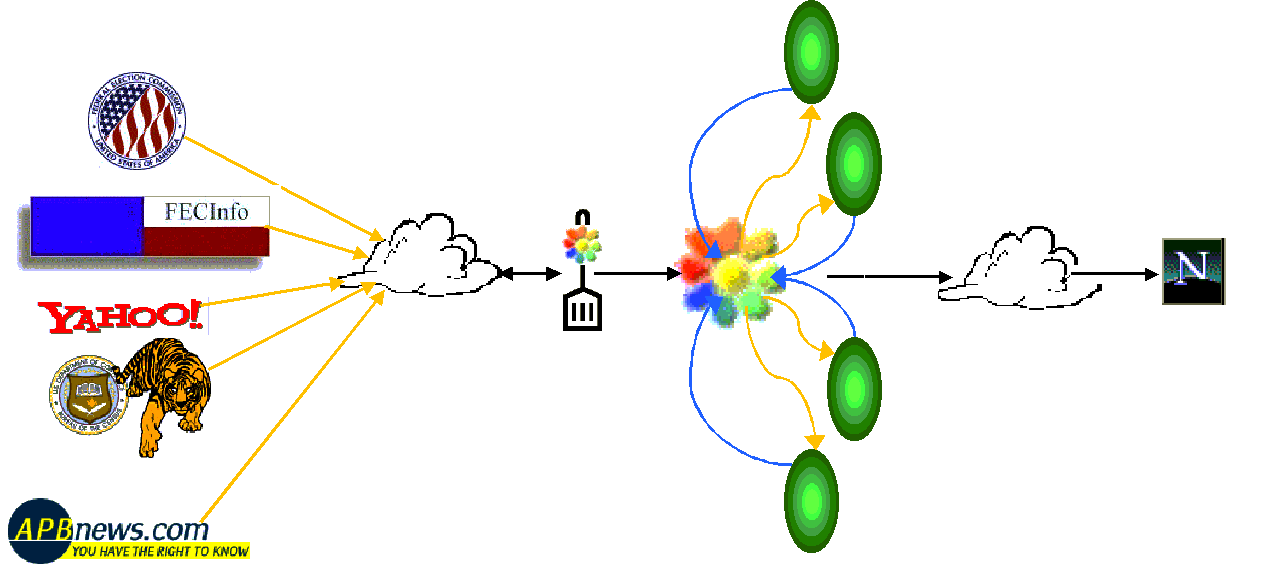
On the far left are publicly available web sites from both companies and the government. These are accessed over the Internet by TESS, the Telegraph Screen Scraper (shown as a spatula in the picture). TESS feeds data into an eddy (the flower), which routes the data adaptively through the four operators (the green ovals), which return data back to the eddy. Once data it ready for output, the eddy sends it over the web to a browser.