NOTE: the document below was written before the HtmlGet shell was available. The document below will outline the steps necessary to extract data from a web page, but a variety of HtmlGet shell commands may be useful in this process:
- showpage
- getselection
- getforms
- betweentags
For more information, please see the HtmlGet documentation here
In the following example we will wrap the results of a simple Google(C) search.
Step 1
Find out what host you will be contacting and what parameters the query needs.
To do this you'll need to look for form tags in the html. In viewing the html source we notice the following form:
<form action="/search" method=get name=f>
<table cellspacing=0 cellpadding=0 ><tr align=center valign=baseline>
<td width=75> </td><td nowrap><font
face=arial,sans-serif size=-1>
Search 1,326,920,000 web pages</font>
</td><td></td></tr>
<tr align=center valign=middle><td width=75> </td><td align=center>
<input type=text value="" framewidth=4 name=q size=55><br>
<input name=btnG type=submit value="Google Search">
<input name=btnI type=submit value="I'm Feeling Lucky">
</td><td nowrap valign=top align=left><font face=arial,sans-serif size=-2>
<a href="/advanced_search">Advanced Search</a><br>
<a href="/preferences">Preferences</a></font></td></tr></table></form>
|
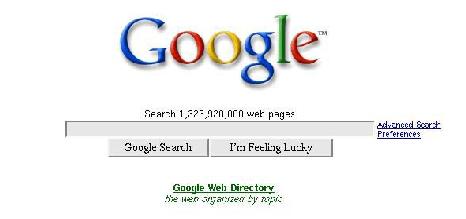
The form that the html to left produces
|
The important information that you'll need is highlighted in bold.
The first thing to notice is the action tag. This tells you what page the form is going to contact when you submit the query.
In this case the action tag points to /search
So in our wrapper file we would add host=www.google.com (since there is no http:// at the start of the action the browser will use the current page as the base and expand the action into http://www.google.com/search) and url=/search?.
So far our wrapper looks like:
host=www.google.com
url=/search?
Now we need to figure out what method this form uses to send the data to the server. The two possibilities in a form are get and post. You can look at the method tag to figure out which one to use. This form happens to use get. See the documentation on query types for more infomation. So now our wrapper looks like:
host=www.google.com
url=/search?
method=get
Now we need to figure out what parameters the query is expecting. To do this find all the input tags in the form and look at thier values. Lucky for this form has only one input we need to worry about. Inputs of type submit and reset you don't need to worry about since they just tell the browser to render a button that submits the query or resets the form and they are not parameters to the query. See the documentation about different input tags for more information. In our query we only need to concern ourselves with the line:
<input type=text value="" framewidth=4 name=q size=55><br>
The important fields here are the value and name fields. The value is the default value for the input, the name is the name of the parameter.
So what we have is a form with one parameter named q that is a text string that defaults to the empty string. To put this the wrapper we would add:
arguments=q,
default1=
Note that the default does not have to be the same as the form default. If you wanted to default to searching for Blue Meanies you could write
arguments=q,
default1=Blue Meanies
and you would have no problems. If we had more arguments (say r and s) we would write (Assuming we wanted the given defaults):
arguments=q,r,s,
default1=Blue Meanies
default2=Moog Cookbook
default3=NOFX
and q would default to Blue Meanies, s to Moog Cookbook and so on.
So now our wrapper looks like:
host=www.google.com
url=/search?
method=get
arguments=q,
default1=
Now we need to tell TESS what results to expect. This is done with the columns tag. For this example we will get the name of the site, the description, and the url. The ordering is important here, the columns need to be listed in the order they appear in the data set. To get this information you'll probably need to run a query.
So now we have:
host=www.google.com
url=/search?
method=get
arguments=q,
default1=
columns=name,description,url,
Step 2
At this point you have fully specified everything TESS needs to know to find the data. Now it's on to telling it how to put that data into tabular form. You'll need to run a sample query on the webpage now. Sometimes different queries can return results differently (for example Mirriam Websters dictionary search will return one type of result if you search for a word it knows about and fairly different kind if you search of one it doesn't know about) so you might need to run a number of sample queries
To run a sample query we will add the dump directive in our wrapper. This tells TESS to dump the html it gets back from running the query and not to try and return any real data. This can be usful both for row/column regular expresion writing but also for debuging the argument part of your script.
For our example lets run a query on "Telegraph". We will change our wrapper to look like:
host=www.google.com
url=/search?
method=get
arguments=q,
default1=telegraph
columns=name,description,url,
dump
end
Looking at the top of the html that gets returned we see:
<html>
<head><META HTTP-EQUIV="content-type" CONTENT="text/html; charset=ISO-8859-1">
<title>Google Search: telegraph </title>
<style><!--
body {font-family: arial,sans-serif;}
div.nav {margin-top: 1ex;}
div.nav A,span.nav {font-size: 10pt; font-family: arial,sans-serif;}
div.nav A,span.big {font-size: 12pt; color: #0000cc;}
div.nav A {font-size: 10pt; color: black;}
A.l:link {color: #6f6f6f;}
//--></style>
</head>
<body bgcolor=#ffffff text=#000000 link=#0000cc vlink=#551A8B alink=#ff0000>
<form method=GET action=/search><table border=0 cellpadding=2
cellspacing=0><tr><td rowspan=2><a href=/><img border=0
src=/intl/en_extra/images/Title_Left.gif width=200 height=78
alt="Google "></a></td><td nowrap><font face=arial,sans-serif
size=-1> <A
HREF=/advanced_search?q=telegraph&lr=&safe=off>Advanced
Search</A> <A
HREF=/preferences?q=telegraph&lr=&safe=off>Preferences</A> <A
HREF=/intl/en_extra/help.html>Search Tips</A></font></td></tr><tr><td
align=left valign=middle><INPUT type=text name=q size=31 maxlength=256
value="telegraph"> <INPUT TYPE=hidden name=lr value=><INPUT
TYPE=hidden name=safe value=off><INPUT type=submit name=btnG
VALUE="Google Search"> <INPUT type=submit name=btnI VALUE="I'm Feeling
Lucky"><br></form>
</td></tr></table>
<table width=100% cellpadding=2 cellspacing=0 border=0><tr><td
bgcolor=#3366cc align=left nowrap><font face=arial,sans-serif size=-1
color=white>Searched the web for <b><a
href=/url?sa=X&q=http://www.dictionary.com/cgi-bin/dict.pl?term=telegraph
title="Look up telegraph on dictionary.com"><font
color=white>telegraph</font></a></b>. </td><td bgcolor=#3366cc
align=right nowrap><font face=arial,sans-serif size=-1
color=white>Results <b>1 - 10</b> of about <b>745,000</b>. Search
took <b>0.07</b> seconds.</font></td></tr></table><br><table border=0
cellpadding=1 cellspacing=0 width=100%><tr><td nowrap><font
color=#6f6f6f size=-1
face=arial,sans-serif>Categories:</font> <font
size=-1 face=arial,sans-serif>
<A href=http://directory.google.com/Top/Recreation/Antiques/Telephones_and_Telegraphs/Telegraphs/>
Recreation > Antiques > Telephones and Telegraphs > Telegraphs</A>
<A href=http://directory.google.com/Top/Recreation/Amateur_Radio/Boatanchors/Morse_Telegraphy/>
Recreation > Amateur Radio > Boatanchors > Morse Telegraphy</A>
</font></td></tr></table>
<p>;<A HREF=http://www.telegraph.co.uk/>Electronic <b>Telegraph</b> |
Front Page</A><font size=-1><br> <b>...</b> the first train operating
company to lose its franchise since privatisation in the<br>
mid-1990s. Yesterday in Parliament Daily <b>Telegraph</b>: Connex
shunted off. <b>...</b>
<br><font size=-1 color=#6f6f6f>Description:</font> Britain's
biggest-selling broadsheet daily. <br><font size=-1
color=#6f6f6f>Category:</font> <a
href=http://directory.google.com/Top/News/Newspapers/Regional/United_Kingdom/
class=l>News > Newspapers > Regional > United Kingdom</a><br><font
color=green>www.telegraph.co.uk/ - 32k - <A
HREF=/search?q=cache:www.telegraph.co.uk/+telegraph class=l>Cached</A>
- <A HREF=/search?lr=&safe=off&num=10&q=related:www.telegraph.co.uk/
class=l>Similar pages</A></font></font><br>
<BLOCKQUOTE>
<p>;<A HREF=http://www.telegraph.co.uk/home.html>Electronic
<b>Telegraph</b> | Front Page</A><font size=-1><br> <b>...</b>
Feedback poll, See text menu at bottom of page Turner Prize 2000<br>
Giorgio Armani <b>Telegraph</b> Money <b>...</b> Search Electronic
<b>Telegraph</b> for. <b>...</b>
<br><font color=green>www.telegraph.co.uk/home.html - 25k - <A
HREF=/search?q=cache:www.telegraph.co.uk/home.html+telegraph
class=l>Cached</A> - <A
HREF=/search?lr=&safe=off&num=10&q=related:www.telegraph.co.uk/home.html
class=l>Similar pages</A></font>
<br>[ <A
HREF=/search?lr=&safe=off&q=site:www.telegraph.co.uk+telegraph
class=l>More results from www.telegraph.co.uk</A> ]
</font><br>
</BLOCKQUOTE>
What the returned results look like:
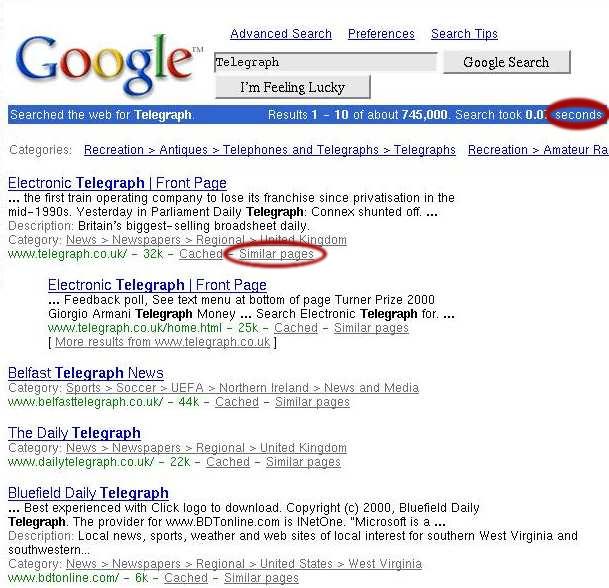
|
Ugg, kinda messy. This is what we need to parse through and
extract meaningful data out of. Note that I've only displayed the HTML for the first two results here but we exploit the fact that most web-based searches return each result in a very similar fashion. It is often useful to use both the HTML and the actual display text. Sometimes certain words in the displayed results will jump out as obvious delimiters, other times certain html tags will be the clear delimiters.
The first thing to look for is some prefix text. Something that signifies that meaningful data is about to follow. The word seconds (circled in red in the picture) seems to appear at the top of the data and will probably appear in all queries so that's what we'll use
prefix=seconds
Now we need to break the data into rows. To do this we need to write regular expresions that match only what we want to act as the beginings and ends of rows. In this case we notice by looking at the html that each new result is prefixed by a paragraph tag at the beginning of a line like <p> (In bold in the above text). We want to only match <p>s that are at the start of lines so we will use the ^ character in our regular expresion. So we have:
rowprefix=^<p>
It also appears that all results end with the text "Similar pages" (circled in red) so we can use that as our rowterm.
rowterm=Similar pages
|
Now our wrapper looks like:
host=www.google.com
url=/search?
method=get
arguments=q,
default1=
columns=name,description,url,
prefix=seconds
rowprefix=^<p>
rowterm=Similar pages
So now we have the google data broken down into rows. All that's left to do is to extract the columns from those rows.
To do this let's look at a single row:
<p><A HREF=http://www.telegraph.co.uk/>Electronic <b>Telegraph</b> |
Front Page</A><font size=-1><br> <b>...</b> the first train operating
company to lose its franchise since privatisation in the<br>
mid-1990s. Yesterday in Parliament Daily <b>Telegraph</b>: Connex
shunted off. <b>...</b>
<br><font size=-1 color=#6f6f6f>Description:</font> Britain's
biggest-selling broadsheet daily. <br><font size=-1
color=#6f6f6f>Category:</font> <a
href=http://directory.google.com/Top/News/Newspapers/Regional/United_Kingdom/
class=l>News > Newspapers > Regional > United Kingdom</a><br><font
color=green>www.telegraph.co.uk/ - 32k - <A
HREF=/search?q=cache:www.telegraph.co.uk/+telegraph class=l>Cached</A>
- <A HREF=/search?lr=&safe=off&num=10&q=related:www.telegraph.co.uk/
class=l>Similar pages
In bold is the data we wish to extract. What we need to do is write a set of prefixes and terminators, similar to how we did for rows, that will extract exactly the data we want. The way to think of this is sequentially. TESS will search through the row for the first column you specify. Once it's found that coloumn it adds it into the result set and keep searching for the next column in the rest of row text. It ignores anything before, or contained within, previous columns.
So what should we use in our example. It would appear that the name of the site is prefixed by a link to it. We can exploit this fact in writing our name_prefix. Since all the varies in a url tag is the url itself we can just write a url matcher:
<A HREF=[^>]*>
should work just fine. (This looks for <A HREF= followed by anything that's not a greater than sign, followed by a greater than sign which is exactly what a link tag is.)
The termination is easy, it's just the end of the link tag, </A> So now we can write our name prefixes and terms:
name_prefix=<A HREF=[^>]*>
name_term=</A>
Tess will now continue searching for the description field in the rest of the row. It seems to be a safe bet that the description will start with the text Description: and end a with a <br&gr;. Similarly we can grab the url by using font color=green> as the prefix and a - as the term. So now our wrapper looks like:
host=www.google.com
url=/search?
method=get
arguments=q,
default1=
columns=name,description,url,
prefix=seconds
rowprefix=^<p>
rowterm=Similar pages
name_prefix=<A HREF=[^>]*>
name_term=</A>
description_prefix=Description:
description_term=<br>
url_prefix=font color=green>
url_term=-
We're almost done! If you look at all the results you will notice that sometimes there is no description of the site. If we were just to leave the wrapper as is TESS would complain because by default it expects to always find all columns. We have to tell it that in this case it's okay for the description to be missing. To do this we use the nullifmissing directive.
description_nullifmissing
We also need to tell tess where it can stop looking for more rows with the termination tag. By looking at the end of the results that google returned:
<p><A HREF=http://www.nbnews.com/telegraphjournal/>The New Brunswick
<b>Telegraph</b> Journal</A><font size=-1><br> <b>...</b> Limbering
up. Noel Chenier/ <b>Telegraph</b>-Journal Adam Mitton is framed by
the legs<br>
of a teammate as he stretches during a running practice in preparation
for the <b>...</b>
<br><font color=green>www.nbnews.com/telegraphjournal/ - 16k - <A
HREF=/search?q=cache:www.nbnews.com/telegraphjournal/+telegraph
class=l>Cached</A> - <A
HREF=/search?lr=&safe=off&num=10&q=related:www.nbnews.com/telegraphjournal/
class=l>Similar pages</A></font></font><br><p><center>
<div class=nav>
<p><table border=0 cellpadding=0 width=10% cellspacing=0><tr
align=center valign=top><td valign=bottom nowrap><font
face=arial,sans-serif size=-1>Result Page: </font></td>
<td><IMG SRC=/intl/en_extra/nav_first.gif alt=""></td>
<td><IMG SRC=/intl/en_extra/nav_current.gif alt=""><br><span
class=nav><font color=#A90A08>1</font></span></td>
it seems that <div class=nav> seems to be a good indicator that the results are finished. As such we will add
termination=<div class=nav>
to our wrapper. We also need to tell TESS that the wrapper is finished by adding an "end" at the end.
So the completed wrapper looks like:
host=www.google.com
url=/search?
method=get
arguments=q,
default1=
columns=name,description,url,
prefix=seconds
rowprefix=^<p>
rowterm=Similar pages
name_prefix=<A HREF=[^>]*>
name_term=</A>
description_prefix=Description:
description_term=<br>
url_prefix=font color=green>
url_term=-
description_nullifmissing
termination=<div class=nav>
end
Congratulations, you've just written your first TESS wrapper!
You can find out how to test it by heading over to testing and debuging wrappers.
Now it's on to bigger and better things in the advanced section.
[Home]
[Tutorial Start]
[Example 1]
[Testing and debuging]